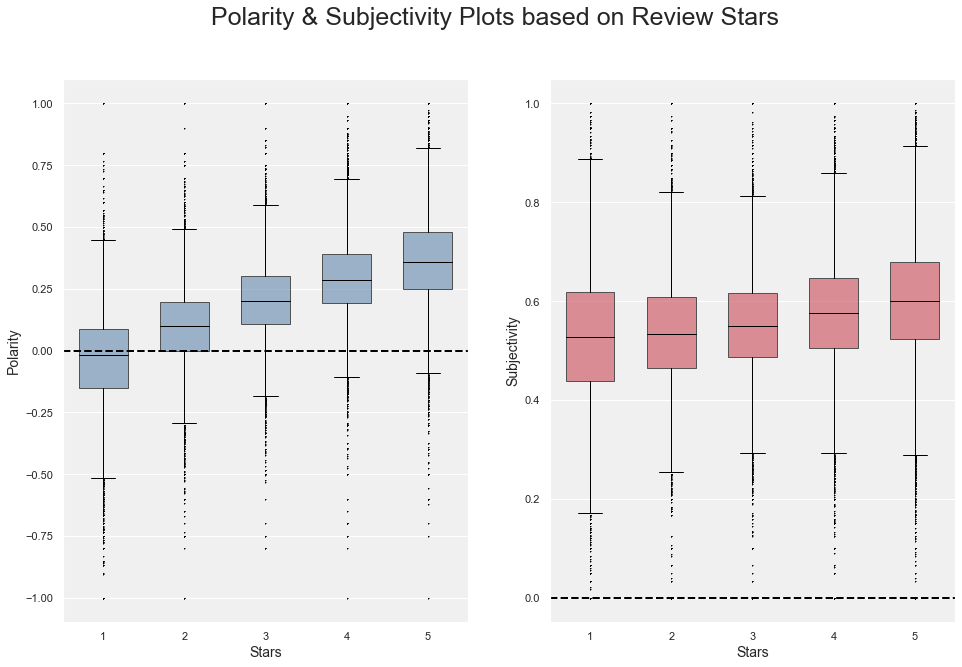
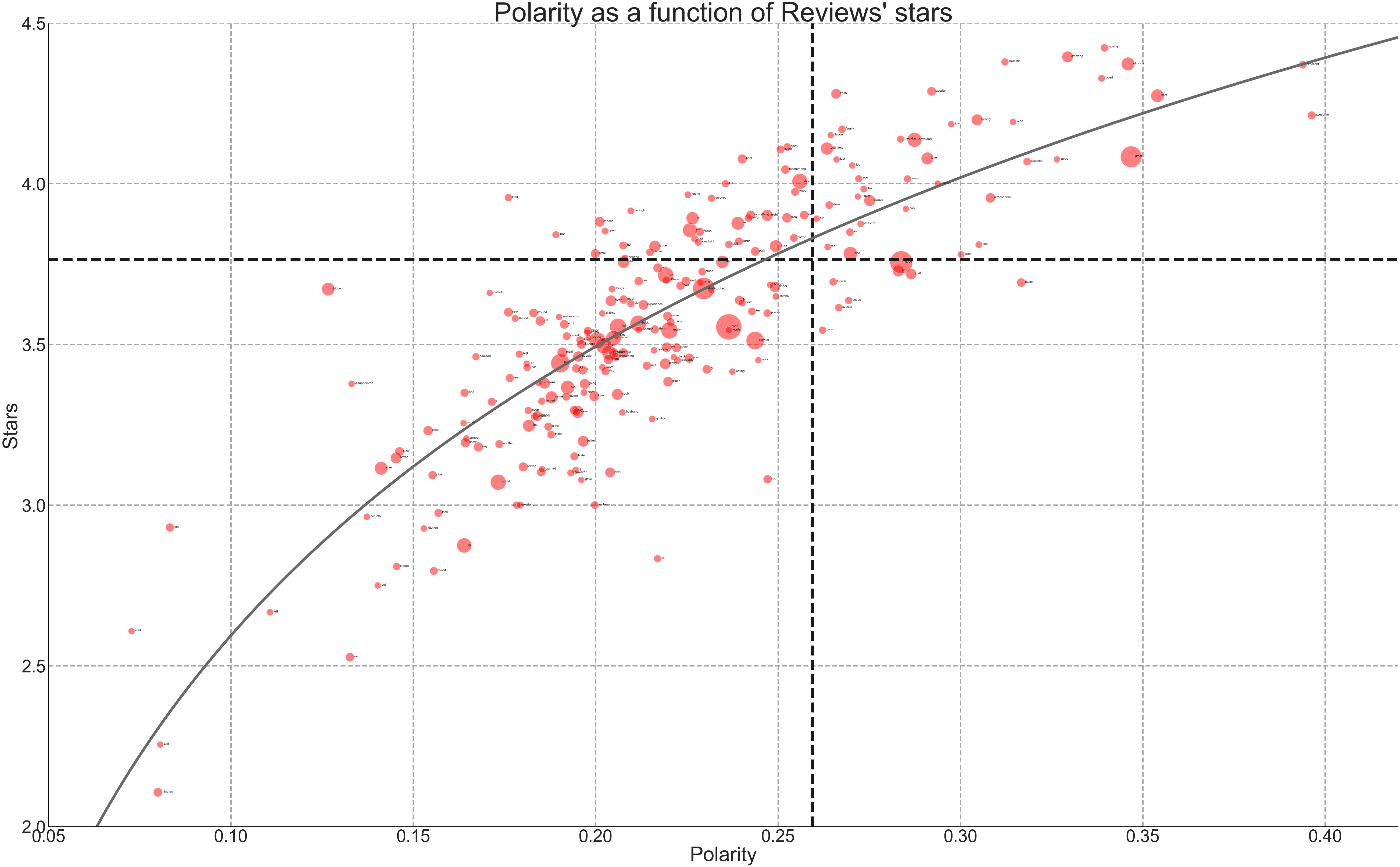
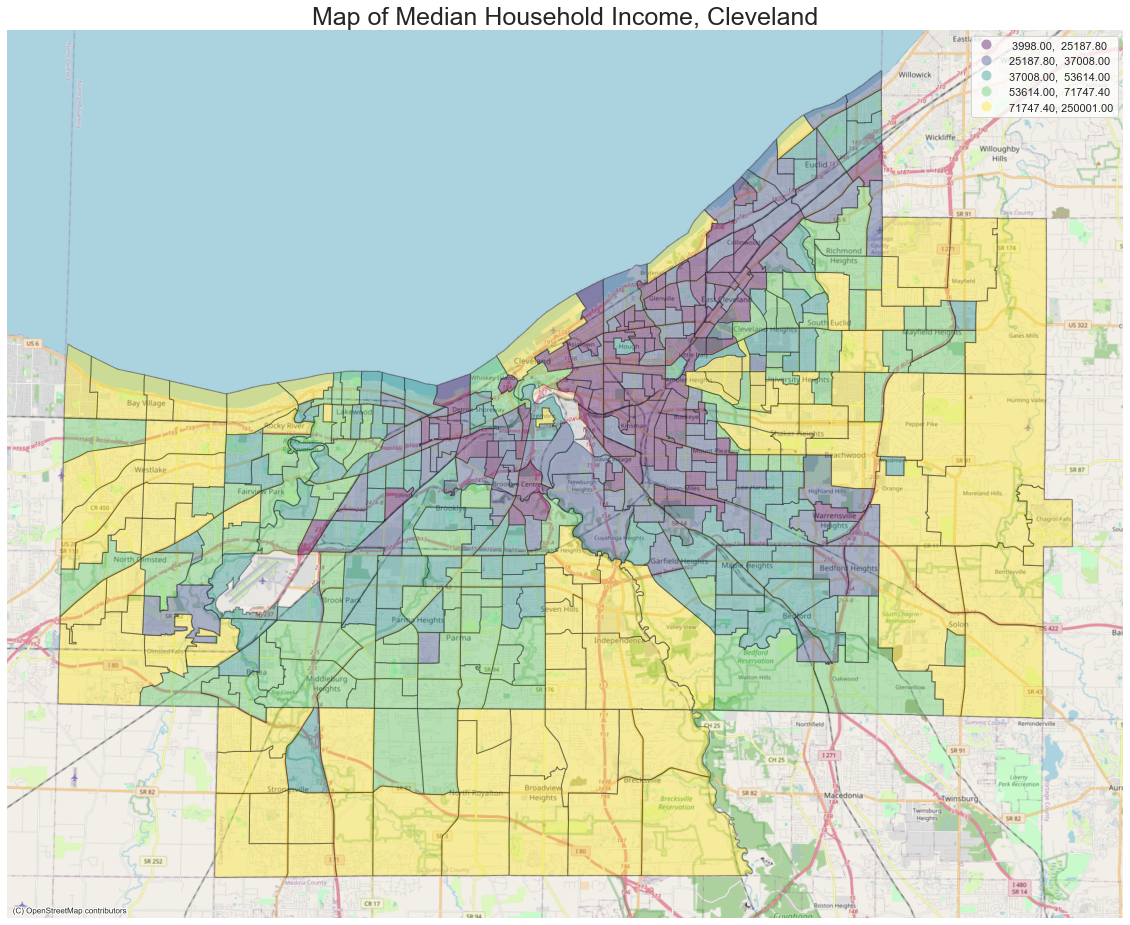
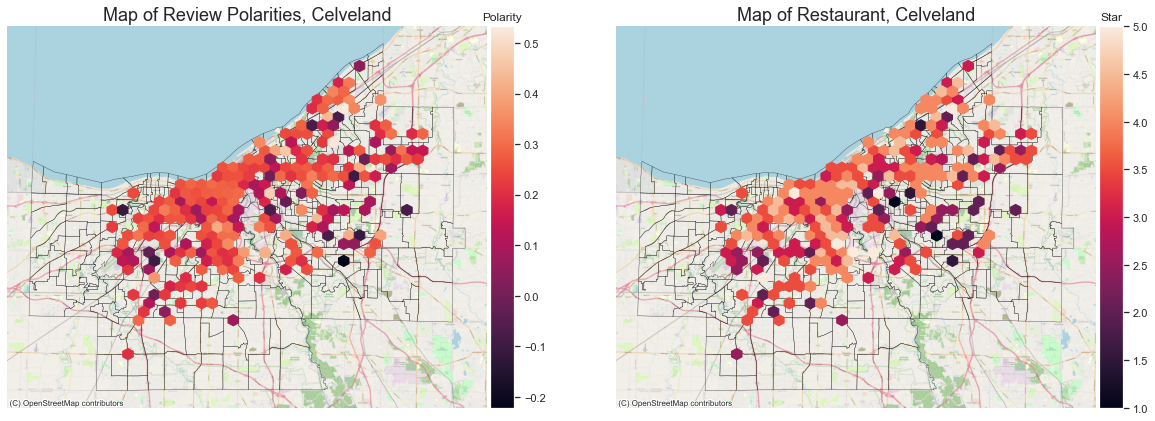
review_clv = pd.read_json("./data/reviews_cleveland.json.gz",orient="records",lines=True)
review_clv["formatted_text"] = review_clv["text"].str.lower()
review_clv["formatted_text"] = review_clv["formatted_text"].str.findall( r'\w+|[^\s\w]+')
stop_words = list(set(nltk.corpus.stopwords.words('english')))
punctuation = list(string.punctuation)
ignored = stop_words + punctuation
review_clv["formatted_text"] = [[i for i in b if i not in ignored] for b in review_clv["formatted_text"]]
for p in punctuation:
review_clv["formatted_text"] = [[i for i in b if not i.startswith (p)] for b in review_clv["formatted_text"]]
blobs = [textblob.TextBlob(" ".join(b)) for b in review_clv["formatted_text"]]
review_clv['polarity'] = [blob.sentiment.polarity for blob in blobs]
review_clv['subjectivity'] = [blob.sentiment.subjectivity for blob in blobs]
# instead of making two plots, a side-by-side plot is made to display the comparison
figure, axes = plt.subplots(1, 2)
figure.suptitle("Polarity & Subjectivity Plots based on Review Stars",fontsize=25)
flierprops = dict(marker='+', markerfacecolor='black', markersize=1, markeredgecolor='black')
sns.set_style("whitegrid")
sns.set(rc={'axes.facecolor':'#F0F0F1'})
boxplot1=sns.boxplot(
y='polarity',
x='stars',
linewidth=1,
data=review_clv,
color="#5687BA",
ax=axes[0],
width=0.6,
flierprops=flierprops)
boxplot2=sns.boxplot(
y='subjectivity',
x='stars',
linewidth=1,
data=review_clv,
color="#E23446",
ax=axes[1],
width=0.6,
flierprops=flierprops)
boxplot1.set_xlabel("Stars", fontsize=14)
boxplot1.set_ylabel("Polarity", fontsize=14)
boxplot2.set_xlabel("Stars", fontsize=14)
boxplot2.set_ylabel("Subjectivity", fontsize=14)
axes[0].axhline(y=0, c='k', lw=2,linestyle='--')
axes[1].axhline(y=0, c='k', lw=2,linestyle='--')
for patch in boxplot1.artists:
r, g, b, a = patch.get_facecolor()
patch.set_facecolor((r, g, b, .6))
for patch in boxplot2.artists:
r, g, b, a = patch.get_facecolor()
patch.set_facecolor((r, g, b, .6))
for line in boxplot1.get_lines():
line.set_color('black')
for line in boxplot2.get_lines():
line.set_color('black')
plt.rcParams["figure.figsize"] = [16,10]
plt.show()